现在很多 AI Agent 产品都在讲 memory:长期记忆、项目记忆、个人偏好、会话历史、知识库、向量检索、自动总结。
这件事很容易让人产生一个错觉:记得越多,Agent 就越聪明。
我的判断正好相反。
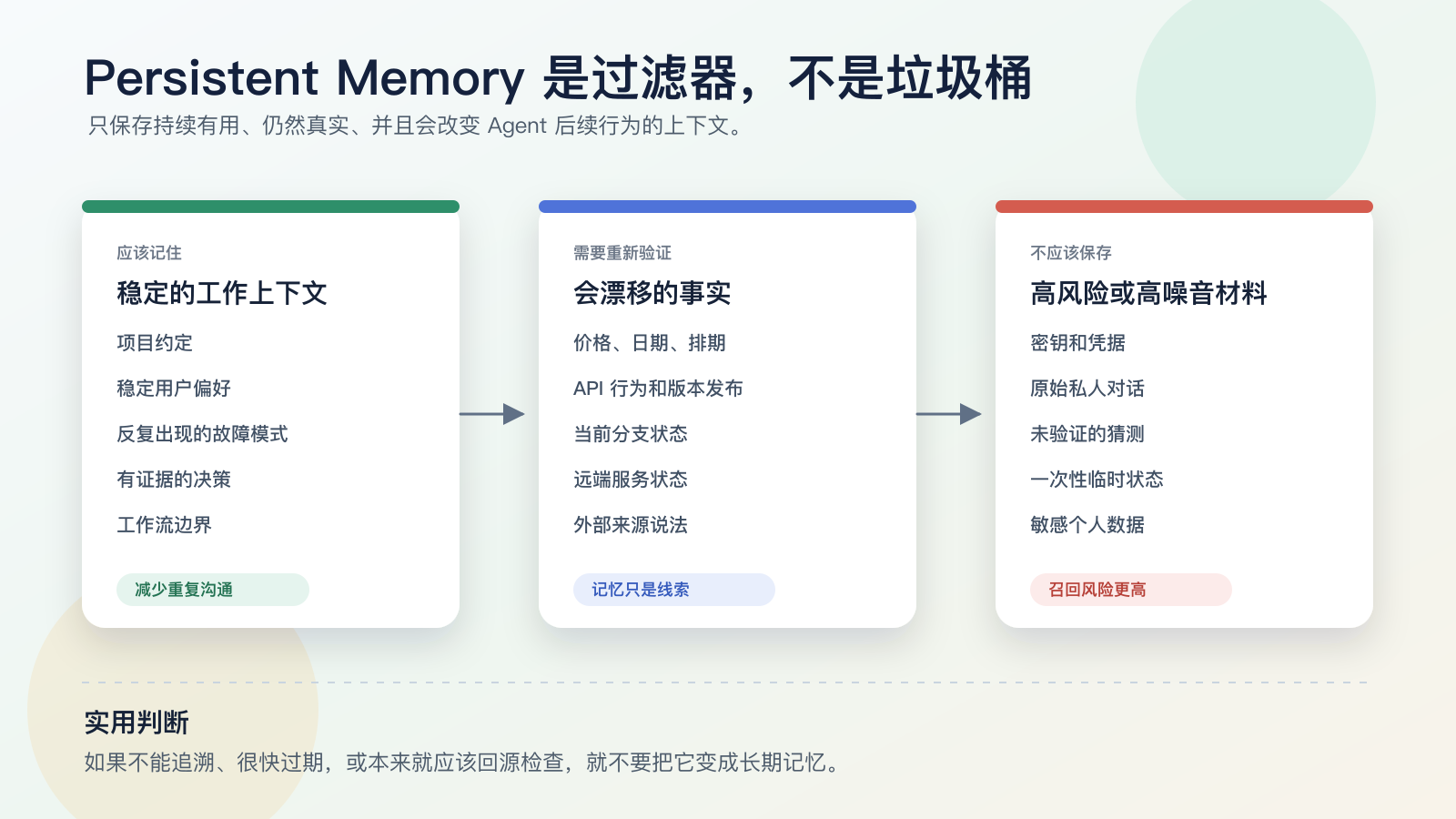
对真正参与工程工作的 Agent 来说,Persistent Memory 不应该是聊天记录垃圾桶,也不应该是“把所有东西都塞进向量库”。它更像一层过滤器:只留下那些稳定、可复用、能改变未来行为的上下文。
否则,memory 会从助力变成噪音。Agent 会拿过期信息当事实,把一次性偏好当永久规则,把未验证猜测当项目结论,甚至把不该保存的敏感内容带到下一次任务里。
先说结论
Agent 最应该记住的,不是“发生过什么”,而是这些信息:
- 未来大概率还会用到;
- 短期内不会快速过期;
- 能减少重复解释;
- 能改变 Agent 的默认行为;
- 有来源、有边界、必要时能重新验证。
反过来,下面这些东西不应该直接变成长期记忆:
- 密钥、密码、token、cookie、恢复码;
- 某次任务里的临时分支状态;
- 价格、排期、版本、政策这类会变化的信息;
- 没有证据的猜测;
- 原始聊天记录和大段私人上下文;
- 一次性的情绪、口头偏好或临时指令。
一句话:memory 是索引,不是档案馆;是工作规则,不是原始日志。
为什么“记得越多”会出问题
普通聊天助手记住你的称呼、语言偏好、写作风格,通常问题不大。但工程 Agent 不一样。它会读代码、改文件、跑命令、接 MCP、调用浏览器、访问内部系统,甚至参与发布流程。
一旦 memory 质量不好,风险会被放大。
比如:
- 它记住“这个项目用 pnpm”,但项目后来迁移到了 bun;
- 它记住“release 分支可以直接部署”,但后来发布规则变成必须和
origin/release完全一致; - 它记住“某个接口返回字段叫
groupName”,但真实 source-of-truth 已经变成displayName; - 它记住“用户不需要测试”,然后在更高风险的后端改动里也跳过测试;
- 它记住某次排障里的临时 SQL,把它当成通用诊断入口。
这些都不是模型能力问题,而是 memory 生命周期问题。
OpenAI 在 ChatGPT memory 文档里把记忆分成 saved memories 和 reference chat history 两类,并强调用户可以管理、删除或关闭记忆能力。这个产品设计背后的重点不是“无限保存”,而是“可控制”。Claude Code 的 memory 设计也把用户级、项目级、目录级记忆拆开,让 CLAUDE.md 这类文件承担不同范围的上下文。
工程 Agent 的 memory 也应该这样分层,而不是把所有上下文混在一起。
三种上下文,不要混用
我更倾向于把 Agent 上下文分成三类。
1. 当前任务上下文
这是最短命的上下文。
比如:
- 当前用户刚说的需求;
- 当前工作树的 diff;
- 当前终端输出;
- 当前浏览器页面状态;
- 本轮排障看到的错误日志;
- 当前计划和待办列表。
这些信息对当前任务很重要,但大多不应该进入长期 memory。任务结束后,它们要么被代码、文档、issue、commit 记录接管,要么就应该自然消失。
如果把当前任务上下文都存进 memory,下一次任务会被旧现场污染。
2. 项目 source-of-truth
这是应该优先相信的上下文。
比如:
AGENTS.md/CLAUDE.md;README.md;Makefile;- CI 配置;
- schema / migration;
- package catalog;
- API 类型定义;
- 测试用例;
- 项目内设计文档。
这些东西不一定叫 memory,但对 Agent 来说,它们就是最重要的可验证记忆。
如果某条 memory 和代码仓库里的 source-of-truth 冲突,应该以仓库为准。memory 只能提示“可能去哪里看”,不能替代真实文件。
3. 长期工作记忆
这才是 Persistent Memory 应该承担的部分。
它记录的是跨任务稳定成立、但不一定已经写进项目文件的协作知识。
比如:
- 用户默认使用中文;
- 某个仓库新增文章要同时生成
.en.md; public目录经常是脏的,文章验证应避免直接构建进去;- 用户明确要求某类 UI 改动不能碰无关界面;
- 某个部署脚本必须保留 linux/amd64,因为本机是 mac arm;
- 某类排障要先查日志,不要先猜修复方案。
这些记忆的价值是减少重复沟通,让 Agent 在下一次任务里更快进入正确边界。
Agent 到底该记住什么?
我会用下面这张表来判断。
| 应该记住 | 例子 | 原因 |
|---|---|---|
| 稳定偏好 | 默认中文、回答简洁、先给结论 | 会持续改变协作方式 |
| 项目惯例 | 新文章放 content/article/,英文版用同 slug .en.md | 能减少重复探索 |
| 硬约束 | 不改后端接口、不碰无关 UI、不要写入 public | 违反会造成真实风险 |
| 反复出现的故障模式 | 某类安装报错来自缓存权限,某类部署慢要看 workflow | 能加速排障 |
| 已确认的业务规则 | 协作者只能加减分,不能改学生数据 | 能避免产品规则回退 |
| 用户认可的方向 | 某个 UI 展示方案已被认可,后续应基于它迭代 | 能保持连续性 |
| 可复用工作流 | 发文后用 hugo --renderToMemory --minify 验证 | 能提高交付稳定性 |
这些信息有一个共同点:它们不是“历史细节”,而是“未来默认动作”。
一条好的 memory 应该能回答这个问题:
下一次遇到相似任务时,Agent 的行为会不会因此变得更正确?
如果答案是否定的,就不要存。
什么应该重新验证?
有些信息可以作为线索,但不能作为事实。
例如:
- 最新 API 用法;
- 当前价格和套餐;
- GitHub Actions 当前状态;
- 远端分支是否已经更新;
- 某个模型是否仍然可用;
- 某个法规、政策、平台规则;
- 当前日期、排期、发布节奏;
- 线上服务是否正常。
这些信息即使曾经正确,也很容易过期。
所以 memory 里最多只能写:
上次排障时,问题出现在 release workflow 的镜像构建阶段。
下次遇到类似发布慢问题,先检查当前 workflow 和最近一次 Actions 日志。而不是写:
发布慢就是因为镜像构建。前者是可复用诊断线索,后者是过期风险很高的结论。
什么绝对不该存?
长期 memory 最危险的不是“不够聪明”,而是“记住了不该记的东西”。
我会把下面几类列入禁止区:
1. secrets 和凭据
包括:
- API key;
- token;
- cookie;
- SSH 私钥;
- 数据库密码;
- 支付后台密钥;
- 恢复码;
- 临时验证码。
这些信息不应该进 memory,也不应该进文章、日志、截图、issue。
2. 原始私人内容
不要把大量聊天原文、邮箱内容、客户资料、订单详情、学生信息、病历、财务记录直接写进 memory。
如果确实需要保留工作上下文,也应该压缩成非敏感规则,例如:
用户处理教育类 SaaS 项目时,很在意老师协作权限和家长端展示边界。而不是保存某个具体学生、家长或订单的原始信息。
3. 未验证猜测
Agent 很容易在排障中形成假设。假设可以存在当前会话里,但不应该沉淀成长期记忆。
只有经过代码、日志、测试、线上验证支撑的结论,才有资格进入 memory。
4. 一次性临时状态
比如:
- 当前正在某个临时分支;
- 某个端口今天被占用;
- 某个文件刚才被生成;
- 某个任务这次不需要测试;
- 某个页面现在打开在 Chrome 第三个标签页。
这些信息应该留在当前任务上下文里,不应该污染长期记忆。
一个简单的保存判断法
我会让每条 memory 通过 5 个问题:
- 下次还会用吗?
- 一个月后大概率还成立吗?
- 能改变 Agent 的默认行为吗?
- 是否能追溯来源或重新验证?
- 如果记错了,会不会造成风险?
只有前四个答案偏“是”,第五个风险可控,才值得保存。
如果一条信息很有用但容易过期,就不要写成事实,写成“下次优先检查哪里”。
如果一条信息风险很高,就不要写进 memory,应该写进项目权限、CI guard、测试、文档或人工审批流程。
Memory 应该怎么写?
好的 memory 应该短、稳定、可执行。
不好的写法:
用户上次让我们改文章,后来 public 脏了,然后用了 hugo 命令,最后好像可以。好的写法:
在 silenceper.com 新增文章时,文章真源是 content/article/;英文版使用同 slug 加 .en.md;验证优先用 hugo --renderToMemory --minify,避免写入 public。差异在于:
- 去掉了过程噪音;
- 保留了未来动作;
- 标明了适用仓库;
- 给出了具体路径和命令;
- 没有把临时现场当事实。
不同信息应该放在哪里?
不是所有长期信息都应该放进同一个 memory 系统。
| 信息类型 | 更适合的位置 |
|---|---|
| 项目硬规则 | AGENTS.md / CLAUDE.md |
| 构建和发布命令 | README.md / Makefile / CI |
| 业务规则 | 代码、测试、产品文档 |
| 用户个人偏好 | 用户级 memory |
| 仓库协作惯例 | 项目级 memory |
| 可复用操作流程 | Skill / runbook |
| 当前任务现场 | 当前会话 / issue / PR 描述 |
| 可变化事实 | 每次重新查源 |
一个成熟的 Agent 工作流,不应该把 memory 当唯一入口。
更好的结构是:
memory 负责提示方向
repo 文件负责定义规则
测试负责防止回退
日志负责还原现场
人工审批负责高风险动作这样 Agent 即使记忆不完整,也能通过 source-of-truth 找回正确上下文。
Persistent Memory 的真正价值
Persistent Memory 最有价值的地方,不是让 Agent 像人一样“什么都记得”。
它的价值是让 Agent 少犯重复错误。
比如:
- 不再每次都问“这个项目用中文还是英文”;
- 不再把已确认的业务规则推翻;
- 不再重复踩同一个部署坑;
- 不再把用户明确拒绝的 UI 方案又拿出来;
- 不再在脏工作树里误改无关文件;
- 不再把需要查代码的套餐信息凭印象回答。
这些看起来都不是宏大的 AGI 能力,但对真实工作非常重要。
工程效率的提升,往往不是来自 Agent 记住了更多碎片,而是来自它记住了更少、更准、更能约束行为的东西。
我的建议
如果你在重度使用 Codex、Claude Code、Cursor 或其他编程 Agent,可以按这个原则管理 memory:
- 把 memory 当索引,不当真源。
- 把稳定规则写进项目文件。
- 把可变化事实留给实时搜索和源码检查。
- 把敏感内容挡在 memory 外面。
- 把每条 memory 写成未来行为,而不是历史流水账。
- 定期清理过期、重复、含糊的记忆。
最终目标不是让 Agent 记住一切,而是让它在下一次工作时更少打扰你、更少跑偏、更少踩坑。
当 memory 变成一套可维护的工程资产,而不是聊天记录堆积物,Agent 才真正开始像一个可靠的长期协作者。
