源码剖析:KEDA是如何工作的?
文章中源码是基于KEDA 2.0( 50bec80 )来进行分析
keda 2.0 要求k8s集群版本 >=1.16
KEDA 在2020年11月4号release了2.0版本,包含了一些新的比较有用的特性,比如ScaledObject/ScaledJob中支持多触发器、支持HPA原始的CPU、Memory scaler等。
具体的安装使用请参考上一篇文章使用keda完成基于事件的弹性伸缩,这篇文章主要深入的看下KEDA内部机制以及是如何工作的。
我们先提出几个问题,带着问题去看代码,方便我们理解整个机制:
- KEDA是如何获取到多种事件的指标,以及如何判断扩缩容的?
- KEDA是如何做到将应用的副本数缩容0,依据是什么?
代码结构
对一些主要目录说明,其他一些MD文件主要是文字说明:
├── BRANDING.md
├── BUILD.md //如何在本地编译和运行
├── CHANGELOG.md
├── CONTRIBUTING.md //如何参与贡献次项目
├── CREATE-NEW-SCALER.md
├── Dockerfile
├── Dockerfile.adapter
├── GOVERNANCE.md
├── LICENSE
├── MAINTAINERS.md
├── Makefile // 构建编译相关命令
├── PROJECT
├── README.md
├── RELEASE-PROCESS.MD
├── adapter // keda-metrics-apiserver 组件入口
├── api // 自定义资源定义,例如ScaledObject的定义
├── bin
├── config //组件yaml资源,通过kustomization工具生成
├── controllers //kubebuilder 中controller 代码控制crd资源
├── go.mod
├── go.sum
├── hack
├── images
├── main.go //keda-operator controller入口
├── pkg //包含组件核心代码实现
├── tests //e2e测试
├── tools
├── vendor
└── versionkeda中主要是两个组件keda-operator以及keda-metrics-apiserver。
- keda-operator : 负责创建/更新HPA以及通过Loop控制应用副本数
- keda-metrics-apiserver:实现external-metrics接口,以对接给HPA的external类型的指标查询(比如各种prometheus指标,mysql等)
keda-operator
项目中用到了kubebuilder SDK,用来完成这个Operator的编写。
对于k8s中的自定义controller不了解的可以看看这边文章:如何在Kubernetes中创建一个自定义Controller?。
keda controller的主要流程,画了幅图:
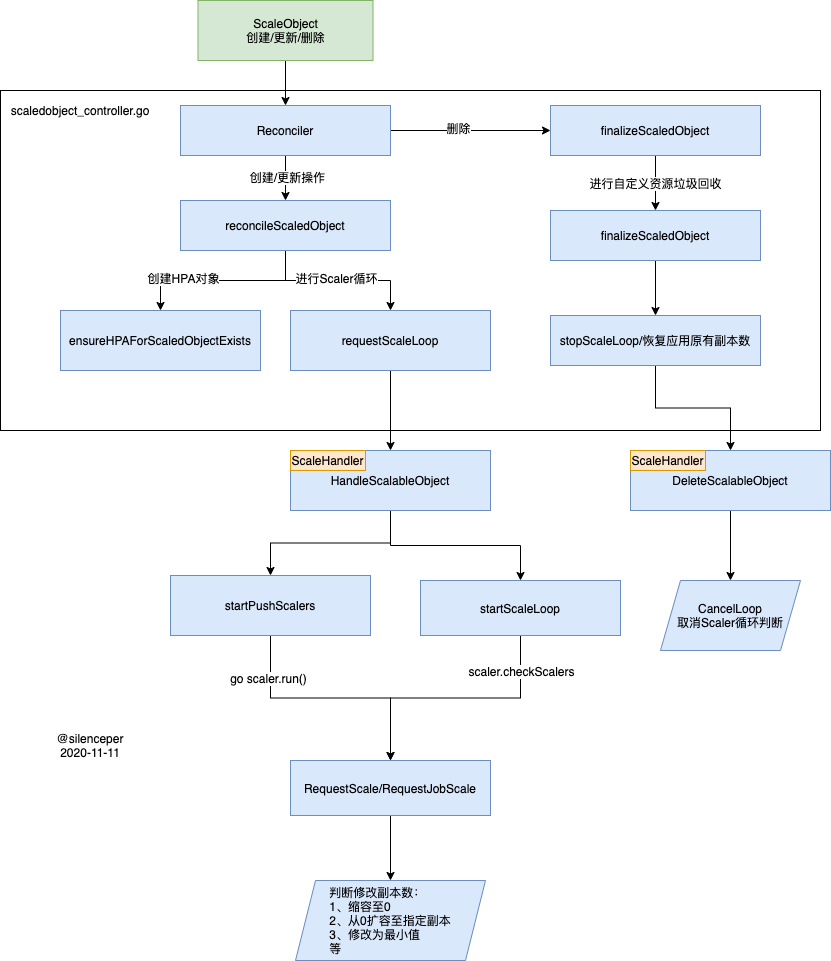
组件启动入口在于main.go文件中:
通过controller-runtime组件启动两个自定义controller:ScaledObjectReconciler,ScaledJobReconciler:
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
HealthProbeBindAddress: ":8081",
Port: 9443,
LeaderElection: enableLeaderElection,
LeaderElectionID: "operator.keda.sh",
})
...
// Add readiness probe
err = mgr.AddReadyzCheck("ready-ping", healthz.Ping)
...
// Add liveness probe
err = mgr.AddHealthzCheck("health-ping", healthz.Ping)
....
//注册 ScaledObject 处理的controller
if err = (&controllers.ScaledObjectReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("ScaledObject"),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "ScaledObject")
os.Exit(1)
}
////注册 ScaledJob 处理的controller
if err = (&controllers.ScaledJobReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("ScaledJob"),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "ScaledJob")
os.Exit(1)
}
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}ScaledObjectReconciler 处理
我们主要关注Reconcile方法,当ScaledObject发生变化时将会触发该方法:
方法内部主要功能实现:
...
// 处理删除ScaledObject的情况
if scaledObject.GetDeletionTimestamp() != nil {
//进入垃圾回收(比如停止goroutine中Loop,恢复原有副本数)
return ctrl.Result{}, r.finalizeScaledObject(reqLogger, scaledObject)
}
// 给ScaledObject资源加上Finalizer:finalizer.keda.sh
if err := r.ensureFinalizer(reqLogger, scaledObject); err != nil {
return ctrl.Result{}, err
}
...
// 真正处理ScaledObject资源
msg, err := r.reconcileScaledObject(reqLogger, scaledObject)
// 设置Status字段说明
conditions := scaledObject.Status.Conditions.DeepCopy()
if err != nil {
reqLogger.Error(err, msg)
conditions.SetReadyCondition(metav1.ConditionFalse, "ScaledObjectCheckFailed", msg)
conditions.SetActiveCondition(metav1.ConditionUnknown, "UnkownState", "ScaledObject check failed")
} else {
reqLogger.V(1).Info(msg)
conditions.SetReadyCondition(metav1.ConditionTrue, "ScaledObjectReady", msg)
}
kedacontrollerutil.SetStatusConditions(r.Client, reqLogger, scaledObject, &conditions)
return ctrl.Result{}, errr.reconcileScaledObject方法:
这个方法中主要两个动作:
ensureHPAForScaledObjectExists创建HPA资源- 进入
requestScaleLoop(不断的检测scaler 是否active,进行副本数的修改)
ensureHPAForScaledObjectExists
通过跟踪进入到newHPAForScaledObject方法:
scaledObjectMetricSpecs, err := r.getScaledObjectMetricSpecs(logger, scaledObject)
...省略代码
hpa := &autoscalingv2beta2.HorizontalPodAutoscaler{
Spec: autoscalingv2beta2.HorizontalPodAutoscalerSpec{
MinReplicas: getHPAMinReplicas(scaledObject),
MaxReplicas: getHPAMaxReplicas(scaledObject),
Metrics: scaledObjectMetricSpecs,
Behavior: behavior,
ScaleTargetRef: autoscalingv2beta2.CrossVersionObjectReference{
Name: scaledObject.Spec.ScaleTargetRef.Name,
Kind: gvkr.Kind,
APIVersion: gvkr.GroupVersion().String(),
}},
ObjectMeta: metav1.ObjectMeta{
Name: getHPAName(scaledObject),
Namespace: scaledObject.Namespace,
Labels: labels,
},
TypeMeta: metav1.TypeMeta{
APIVersion: "v2beta2",
},
}可以看到创建ScalerObject其实最终也是创建了HPA,其实还是通过HPA本身的特性来控制应用的弹性伸缩。
其中getScaledObjectMetricSpecs方法中就是获取到triggers中的metrics指标。
这里有区分一下External的metrics和resource metrics,因为CPU/Memory scaler是通过resource metrics 来获取的。
requestScaleLoop
requestScaleLoop方法中用来循环check Scaler中的IsActive状态并作出对应的处理,比如修改副本数,直接来看最终的处理吧:
这里有两种模型来触发RequestScale:
- Pull模型:即主动的调用scaler 中的
IsActive方法 - Push模型:由Scaler来触发,
PushScaler多了一个Run方法,通过channel传入active状态。
IsActive是由Scaler实现的,比如对于prometheus来说,可能指标为0则为false
这个具体的scaler实现后续再讲,我们来看看RequestScale做了什么事:
//当前副本数为0,并是所有scaler属于active状态,则修改副本数为MinReplicaCount 或 1
if currentScale.Spec.Replicas == 0 && isActive {
e.scaleFromZero(ctx, logger, scaledObject, currentScale)
} else if !isActive &&
currentScale.Spec.Replicas > 0 &&
(scaledObject.Spec.MinReplicaCount == nil || *scaledObject.Spec.MinReplicaCount == 0) {
// 所有scaler都处理not active状态,并且当前副本数大于0,且MinReplicaCount设定为0
// 则缩容副本数为0
e.scaleToZero(ctx, logger, scaledObject, currentScale)
} else if !isActive &&
scaledObject.Spec.MinReplicaCount != nil &&
currentScale.Spec.Replicas < *scaledObject.Spec.MinReplicaCount {
// 所有scaler都处理not active状态,并且当前副本数小于MinReplicaCount,则修改为MinReplicaCount
currentScale.Spec.Replicas = *scaledObject.Spec.MinReplicaCount
err := e.updateScaleOnScaleTarget(ctx, scaledObject, currentScale)
....
} else if isActive {
// 处理active状态,并且副本数大于0,则更新LastActiveTime
e.updateLastActiveTime(ctx, logger, scaledObject)
} else {
// 不处理
logger.V(1).Info("ScaleTarget no change")
}ScaledJobReconciler 处理
ScaledJobReconciler相比ScalerObject少了创建HPA的步骤,其余的步骤主要是通过checkScaledJobScalers,RequestJobScale两个方法来判断Job创建:
checkScaledJobScalers方法,用于计算isActive,maxValue的值RequestJobScale方法,用于负责创建Job,里面还涉及到三种扩容策略
这里直接看代码吧,不贴代码了。
如何停止Loop
这里有个问题就是startPushScalers和startScaleLoop都是在Goroutine中处理的,所以当ScaleObject/ScalerJob被删除的时候,这里需要能够被删除,这里就用到了context.Cancel方法,在Goroutine启动的时候就将,context保存在scaleLoopContexts *sync.Map中(如果已经有了,就先Cancel一次),在删除资源的时候,进行删除:
func (h *scaleHandler) DeleteScalableObject(scalableObject interface{}) error {
withTriggers, err := asDuckWithTriggers(scalableObject)
if err != nil {
h.logger.Error(err, "error duck typing object into withTrigger")
return err
}
key := generateKey(withTriggers)
result, ok := h.scaleLoopContexts.Load(key)
if ok {
cancel, ok := result.(context.CancelFunc)
if ok {
cancel()
}
h.scaleLoopContexts.Delete(key)
} else {
h.logger.V(1).Info("ScaleObject was not found in controller cache", "key", key)
}
return nil
}ps: 这里的妙啊,学到了
keda-metrics-apiserver
keda-metrics-apiserver实现了ExternalMetricsProvider接口:
type ExternalMetricsProvider interface {
GetExternalMetric(namespace string, metricSelector labels.Selector, info ExternalMetricInfo) (*external_metrics.ExternalMetricValueList, error)
ListAllExternalMetrics() []ExternalMetricInfo
}- GetExternalMetric 用于返回Scaler的指标,调用
scaler.GetMetrics方法 - ListAllExternalMetrics 返回所有支持的external metrics,例如prometheus,mysql等
当代码写好之后,再通过apiservice注册到apiservier上(当然还涉及到鉴权,这里不啰嗦了):
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
app.kubernetes.io/name: v1beta1.external.metrics.k8s.io
app.kubernetes.io/version: latest
app.kubernetes.io/part-of: keda-operator
name: v1beta1.external.metrics.k8s.io
spec:
service:
name: keda-metrics-apiserver
namespace: keda
group: external.metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100实现一个Scaler
其实有两种Scaler,即上面将的一个pull,一个push的模型,PushScaler多了一个Run方法:
实现一个Scaler,主要实现以下接口:
// Scaler interface
type Scaler interface {
// 返回external_metrics.ExternalMetricValue对象,其实就是用于 keda-metrics-apiserver中获取到scaler的指标
GetMetrics(ctx context.Context, metricName string, metricSelector labels.Selector) ([]external_metrics.ExternalMetricValue, error)
// 返回v2beta2.MetricSpec 结构,主要用于ScalerObject描述创建HPA的类型和Target指标等
GetMetricSpecForScaling() []v2beta2.MetricSpec
// 返回该Scaler是否Active,可能会影响Loop中直接修改副本数
IsActive(ctx context.Context) (bool, error)
//调用完一次上面的方法就会调用一次Close
Close() error
}
// PushScaler interface
type PushScaler interface {
Scaler
// 通过scaler实现Run方法,往active channel中,写入值,而非上面的直接调用IsActive放回
Run(ctx context.Context, active chan<- bool)
}总结
回过头来我们解答下在开头留下的问题:
KEDA是如何获取到多种事件的指标,以及如何判断扩缩容的?
答:keda controler中生成了external 类型的hpa,并且实现了external metrics 的api
KEDA是如何做到将应用的副本数缩容0,依据是什么?
答: keda 内部有个loop,不断的check isActive状态,会主动的修改应用副本
