KEDA - 一个基于事件驱动的伸缩控制器
KEDA - 一个基于事件驱动的伸缩控制器
November 4, 2020
keda是一个基于事件驱动的伸缩控制器,可以实现应用缩容至0,以及从0开始扩容。目前已支持像CPU/Memroy、Mysql、Prometheus、Redis等20多种事件来源(Scaler)。
目前也是CNCF下的sandbox项目,最初主要由微软、redhat以及社区的人员参与贡献。
网站:https://keda.sh/
项目地址:https://github.com/kedacore/keda
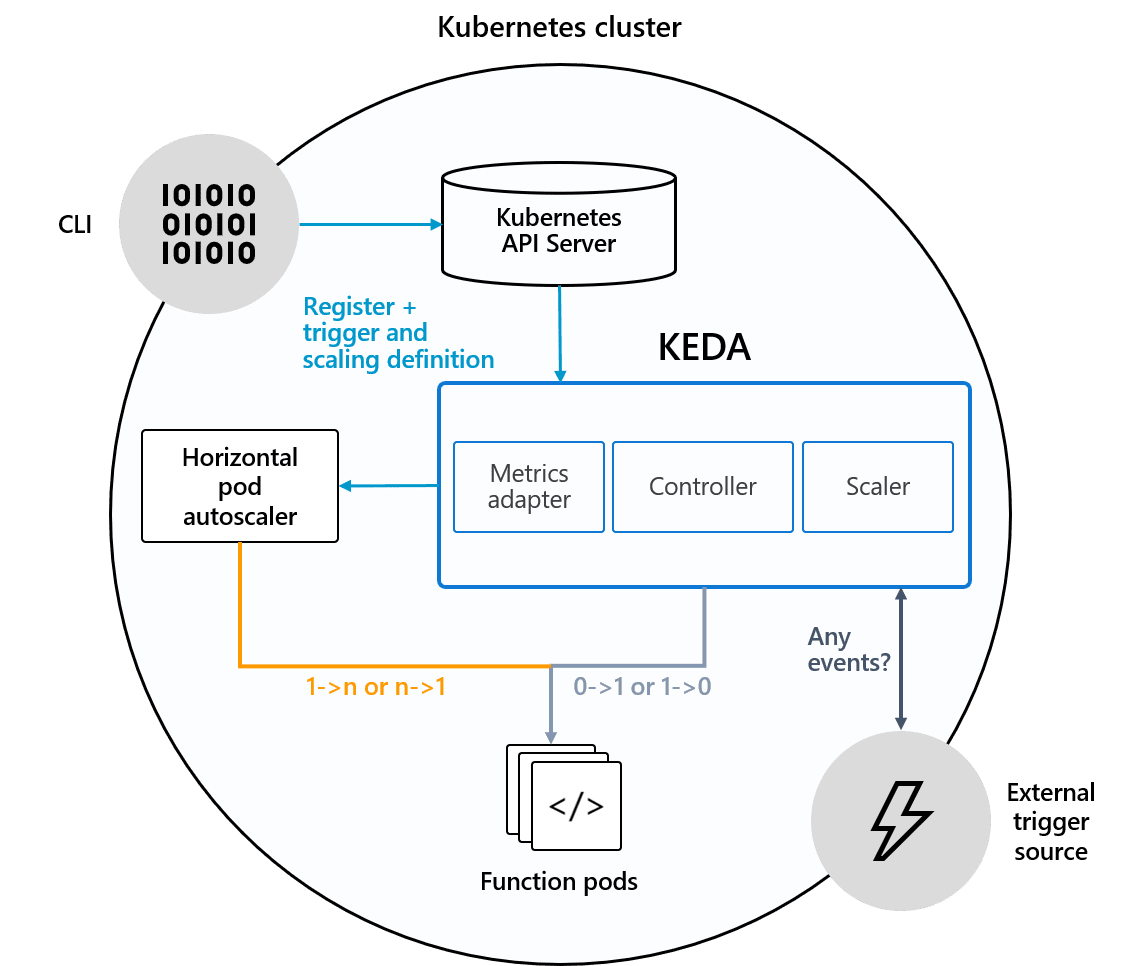
KEDA架构图:
安装
keda 2.0版本要求k8s集群>=1.16
支持多种安装方式,可以查看keda文档:https://keda.sh/docs/2.0/deploy/#install
比如直接使用YAML文件安装:
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.0.0/keda-2.0.0.yaml检查集群中是否安装成功:
>kubectl get pod -n keda
NAME READY STATUS RESTARTS AGE
keda-metrics-apiserver-5bffbfbd68-s7pbn 1/1 Running 10 2d23h
keda-operator-7b98595dc7-tvgr9 1/1 Running 19 2d23h基本使用
KEDA 2.0有两种控制对象:
- ScaledObject:基于HPA,根据事件触发器(scaler)控制应用(Deployments, StatefulSets & Custom Resources)的水平伸缩
- ScaledJob:根据事件触发器(scaler),生成job
###ScaledObject配置
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}参数说明:
| 参数 | 说明 |
|---|---|
| spec.scaleTargetRef | 需要扩缩容的对象资源 |
| spec.pollingInterval | 定时获取触发器(scaler)的时间间隔,默认30s |
| spec.cooldownPeriod | 上次active至缩容为0需要等待的时间,默认300s |
| spec.minReplicaCount | 应用最小值 |
| spec.maxReplicaCount | 应用最大值 |
| spec.advanced.restoreToOriginalReplicaCount | 在删除ScaledObject之后,是否将应用恢复为原值 |
| spec.advanced.horizontalPodAutoscalerConfig | HPA对应的配置 |
| spec.triggers | scaler列表 |
比如创建一个基于prometheus的数据作为触发器的scaledobject:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
spec:
scaleTargetRef:
deploymentName: http-demo
minReplicaCount: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://192.168.99.100:31046/
metricName: gin_requests_total
threshold: '2'
query: sum(rate(gin_requests_total{app="http-demo",code="200"}[2m]))###Scaling Jobs配置
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}参数说明:
| 参数 | 说明 |
|---|---|
| spec.jobTargetRef | 生成的job描述, |
| spec.pollingInterval | 定时获取触发器(scaler)的时间间隔,默认30s |
| spec.successfulJobsHistoryLimit | 保留的success job数量 |
| spec.failedJobsHistoryLimit | 保留的failed job数量 |
| spec.envSourceContainerName | 通过环境变量设置参数的容器,比如“iam.amazonaws.com/role”参数等 |
| spec.maxReplicaCount | job最大数量 |
| spec.scalingStrategy | job生成策略 |
| spec.triggers | scaler列表 |
Scaler
支持的Scaler如下:
- ActiveMQ Artemis
- Apache Kafka
- AWS CloudWatch
- AWS Kinesis Stream
- AWS SQS Queue
- Azure Blob Storage
- Azure Event Hubs
- Azure Log Analytics
- Azure Monitor
- Azure Service Bus
- Azure Storage Queue
- CPU
- Cron
- External
- External Push
- Google Cloud Platform Pub/Sub
- Huawei Cloudeye
- IBM MQ
- Liiklus Topic
- Memory
- Metrics API
- MySQL
- NATS Streaming
- PostgreSQL
- Prometheus
- RabbitMQ Queue
- Redis Lists
- Redis Streams
标签
相关文章
基于标签推荐